卷积神经网络#
全连接神经网络揭示了全连接网络的致命缺陷:用235,000个参数处理28×28图像,效率极其低下。本节介绍的CNN通过巧妙设计,将参数量减少到几千个,同时提升性能——这就是参数效率的飞跃。
参数效率:CNN vs 全连接#
架构 |
参数量 |
MNIST准确率 |
归纳偏置 |
参数效率 |
|---|---|---|---|---|
全连接 |
~235K |
~98% |
弱 |
低 |
CNN |
~60K |
~99% |
局部性+平移不变性 |
高 |
关键问题:CNN如何用1/4的参数达到更好的效果?
答案就在它的归纳偏置设计中:
局部感受野:3×3卷积核只看相邻9个像素,而非全部784个
权值共享:同一个卷积核滑过整张图像,参数重复使用
这正是我们在归纳偏置(Inductive Bias)中讨论的核心概念——CNN将"图像是二维的"、"相邻像素相关"这些先验知识内置到架构中。
感受野#
感受野(Receptive Field) 是理解 CNN 最重要的概念之一。它定义为输出特征图上的一个神经元对应到输入图像上的区域大小。简单说:一个神经元"看到"了输入图像上多大一个区域。
第1层卷积:\(3 \times 3\) 卷积核,感受野 = \(3 \times 3\)(只看相邻像素)
第2层卷积:堆叠两个 \(3 \times 3\),感受野 = \(5 \times 5\)(看到更广的区域)
第3层卷积:堆叠三个 \(3 \times 3\),感受野 = \(7 \times 7\)
递推公式:感受野 = 前一层感受野 + (卷积核大小 - 1) × 累积步长
感受野随着网络深度线性增长。这也是为什么需要深层网络——层数越多,每个神经元能捕获的上下文信息越丰富。但标准 CNN 有一个限制:训练完成后,感受野对所有输入是固定的——无论输入是猫还是汽车,每个神经元都看到同样大小的区域。
卷积操作的基本原理#
卷积操作是CNN的核心,它通过滑动窗口的方式在输入图像上应用(通过点积)滤波器(卷积核)来提取特征。这种思想最早由LeCun等人在1989年提出 [LBD+89],并在后续的LeNet-5工作中 [LBBH98] 得到完善。
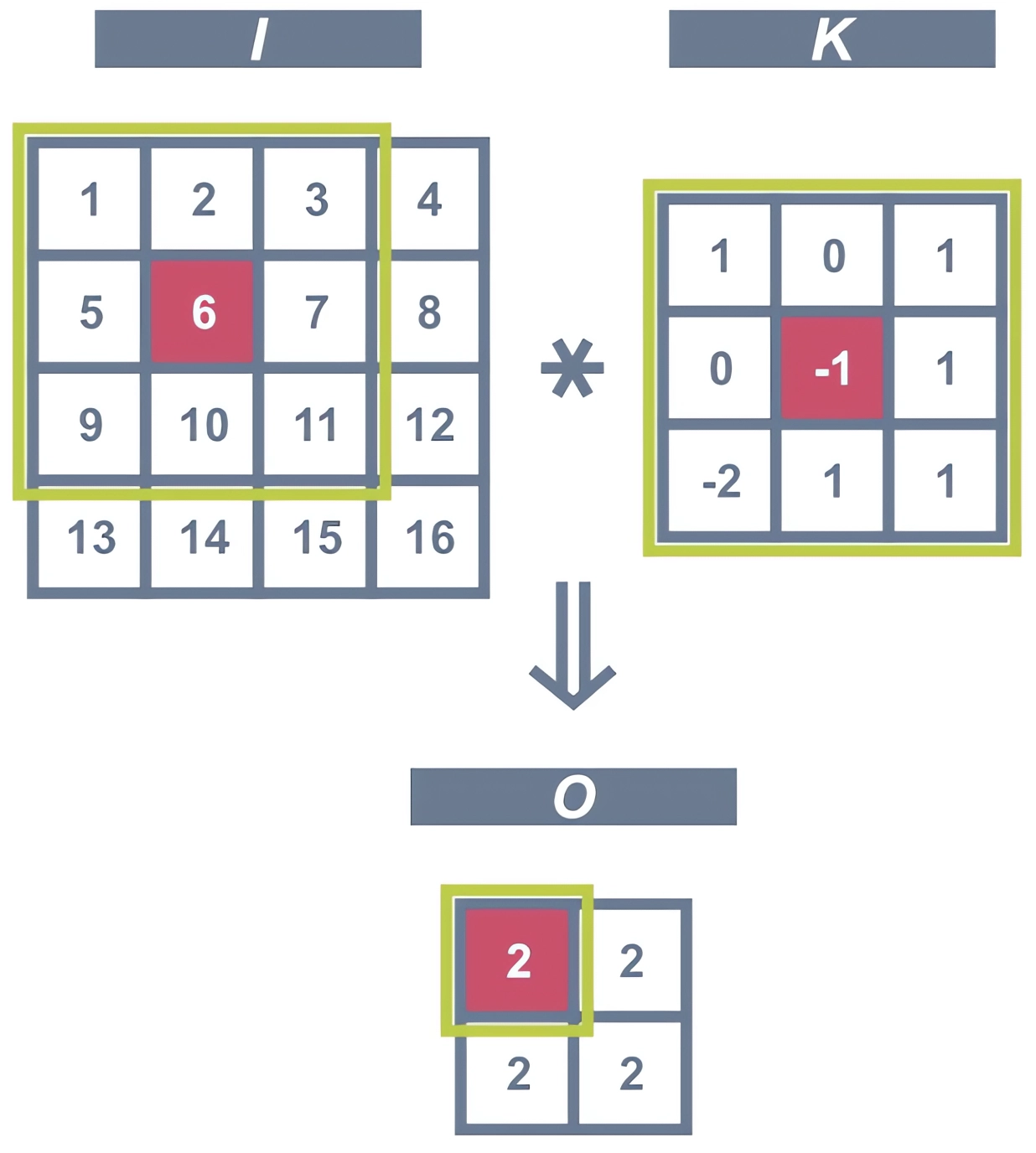
卷积操作示意图#
备注
卷积操作的数学定义
在离散图像处理中,卷积操作可以表示为:
其中:
\(X\):输入特征图
\(K\):卷积核(滤波器)
\(b\):偏置项
\(k\):卷积核大小
直觉:卷积核为什么能提取特征?#
卷积核提取特征的原理其实很直观:点积 = 相似度度量。
回想一下两个向量的点积:\(\mathbf{a} \cdot \mathbf{b} = \sum_i a_i b_i\)。当两个向量方向一致时,点积最大;方向相反时,点积为负。换句话说,点积衡量了两个向量的相似程度。
卷积操作就是反复做点积:

卷积核=模式匹配器
这个 3×3 的卷积核左边全是 -1、中间是 0、右边全是 1——它检测的是垂直边缘:
当图像局部区域的左边暗、右边亮(如 \(\begin{bmatrix}0 & 0 & 1\\0 & 0 & 1\\0 & 0 & 1\end{bmatrix}\)),点积结果是正数(上图结果是 3),说明"这里有垂直边缘"
如果图像区域是均匀的(如全是 0),点积结果是 0,说明"这里没有边缘"
如果左边亮右边暗,点积结果是负数,说明"这里有反方向的边缘"
不同的卷积核检测不同的模式:
卷积核 |
检测的特征 |
示例数值 |
响应条件 |
|---|---|---|---|
垂直边缘 |
左右亮度突变 |
\(\begin{bmatrix}-1 & 0 & 1\\-1 & 0 & 1\\-1 & 0 & 1\end{bmatrix}\) |
左暗右亮 → 正响应 |
水平边缘 |
上下亮度突变 |
\(\begin{bmatrix}-1 & -1 & -1\\0 & 0 & 0\\1 & 1 & 1\end{bmatrix}\) |
上暗下亮 → 正响应 |
角点检测 |
对角线变化 |
对角线模式 |
特定方向变化 |
纹理检测 |
重复的局部图案 |
训练得到 |
匹配特定纹理 |
训练过程中,卷积核的数值通过反向传播自动调整——网络自己"学会"了要检测什么特征。浅层学边缘、深层学语义,这就是 归纳偏置(Inductive Bias) 中讨论的层次特征提取。
简单来说,卷积操作就是拿着一个个"模板"(卷积核)在图像上滑动,在每个位置计算模板和该区域的相似度。相似的区域得到高响应,不相似的得到低响应。32 个卷积核就是 32 个不同的模板,各自关注不同的模式。
特征图尺寸计算#
对于输入尺寸为 \(W \times H\),卷积核大小为 \(K \times K\),步长为 \(S\),填充为 \(P\) 的情况,输出特征图的尺寸为:
MNIST实例计算
对于28×28的MNIST图像,使用3×3卷积核,步长S=1,填充P=1:
输出宽度:\(W_{out} = \lfloor \frac{28 - 3 + 2 \times 1}{1} \rfloor + 1 = 28\)
输出高度:\(H_{out} = \lfloor \frac{28 - 3 + 2 \times 1}{1} \rfloor + 1 = 28\)
结论:输出特征图尺寸保持28×28不变
如果使用2×2池化,步长S=2,无填充P=0:
输出尺寸:\(W_{out} = \lfloor \frac{28 - 2 + 0}{2} \rfloor + 1 = 14\)
结论:池化将特征图尺寸减半
参数共享机制#
卷积层的一个重要特性是参数共享。同一个卷积核在图像的不同位置重复使用,这大大减少了参数数量。
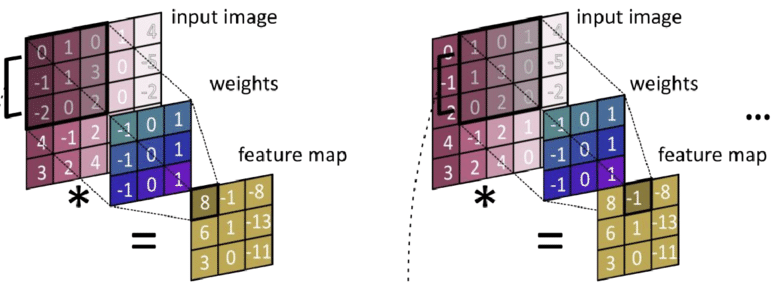
参数共享机制示意图#
对于 \(C_{\text{out}}\) 个输出通道,每个通道使用独立的卷积核:
其中 \(C_{in}\) 是输入通道数。
以MNIST为例(单通道输入,32个3×3卷积核):
相比全连接层的数万参数,卷积层的参数数量显著减少了99%以上。
卷积层的优势#
卷积层的核心优势
局部连接:每个神经元只连接输入图像的局部区域
权值共享:同一卷积核在整个图像上滑动,大幅减少参数
平移不变性:相同特征在不同位置被同一卷积核检测
层次特征提取:浅层提取边缘等低级特征,深层提取语义等高级特征
池化层#
池化层用于降采样,减少特征图的空间尺寸:
最大池化(Max Pooling):取局部区域的最大值
平均池化(Average Pooling):取局部区域的平均值
池化操作不提供可学习参数,但能有效减少计算量和过拟合风险。
PyTorch实现CNN#
import torch
import torch.nn as nn
import torch.nn.functional as F
class SimpleCNN(nn.Module):
def __init__(self, num_classes=10):
super(SimpleCNN, self).__init__()
# 第一个卷积块:1 -> 32通道
self.conv1 = nn.Conv2d(1, 32, kernel_size=3, padding=1)
self.bn1 = nn.BatchNorm2d(32)
# 第二个卷积块:32 -> 64通道
self.conv2 = nn.Conv2d(32, 64, kernel_size=3, padding=1)
self.bn2 = nn.BatchNorm2d(64)
# 池化层
self.pool = nn.MaxPool2d(2, 2)
# 全连接层
self.fc1 = nn.Linear(64 * 7 * 7, 128)
self.fc2 = nn.Linear(128, num_classes)
self.dropout = nn.Dropout(0.5)
def forward(self, x):
# 第一个卷积块:28x28 -> 14x14
# conv1: 输入1通道,输出32通道,3x3卷积核,参数量32*(3*3*1+1)=320
x = self.conv1(x) # {ref}`computational-graph`中的卷积节点
x = self.bn1(x) # 批归一化 {cite}`ioffe2015batch`,稳定训练
x = F.relu(x) # 非线性激活(见{ref}`activation-functions`)
x = self.pool(x) # 下采样:28x28 -> 14x14
# 第二个卷积块:14x14 -> 7x7
# conv2: 输入32通道,输出64通道,参数量64*(3*3*32+1)=18,496
x = self.conv2(x)
x = self.bn2(x)
x = F.relu(x)
x = self.pool(x) # 14x14 -> 7x7
# 展平:64通道 × 7x7 = 3,136维向量
# 对比全连接:直接从784展平,CNN先提取特征再展平
x = x.view(x.size(0), -1)
# 全连接层:3,136 -> 128 -> 10
x = self.fc1(x)
x = F.relu(x)
x = self.dropout(x) # 正则化,防止过拟合
x = self.fc2(x) # 输出logits,CrossEntropyLoss内部Softmax
return x
def get_param_count(self):
"""计算各层参数数量,验证参数效率"""
conv1_params = 32 * (3*3*1 + 1) # 320
conv2_params = 64 * (3*3*32 + 1) # 18,496
fc1_params = 64*7*7 * 128 + 128 # 401,536
fc2_params = 128 * 10 + 10 # 1,290
total = conv1_params + conv2_params + fc1_params + fc2_params
return {
'conv1': conv1_params,
'conv2': conv2_params,
'fc1': fc1_params,
'fc2': fc2_params,
'total': total
}
# 模型实例化
model = SimpleCNN()
param_info = model.get_param_count()
print("=" * 50)
print("CNN参数效率分析")
print("=" * 50)
print(f"卷积层参数:")
print(f" Conv1 (32通道): {param_info['conv1']:,} 参数")
print(f" Conv2 (64通道): {param_info['conv2']:,} 参数")
print(f"全连接层参数:")
print(f" FC1 (128神经元): {param_info['fc1']:,} 参数")
print(f" FC2 (10类别): {param_info['fc2']:,} 参数")
print(f"-" * 50)
print(f"总参数数量: {param_info['total']:,}")
print(f"对比全连接: 235,146 参数")
print(f"参数减少: {235146 - param_info['total']:,} ({(1 - param_info['total']/235146)*100:.1f}%)")
print("=" * 50)
特征图:CNN的"眼睛"#
每层卷积都在学习什么?通过可视化特征图,我们可以"看到"CNN的感知过程:
层级 |
特征图内容 |
人类可理解性 |
作用 |
|---|---|---|---|
Conv1 (32通道) |
边缘、纹理、颜色梯度 |
⭐⭐⭐ 高 |
像边缘检测器,识别笔画边界 |
Conv2 (64通道) |
笔画、弧线、角点 |
⭐⭐☆ 中 |
组合低级特征,识别数字部件 |
池化后 |
抽象的位置信息 |
⭐☆☆ 低 |
降维同时保留关键特征 |
FC层 |
数字类别的高层表示 |
⭐☆☆ 低 |
完全抽象,人类难以理解 |

CNN分层特征提取示意
分层学习的启示:
CNN自动学习从简单到复杂的特征层次,无需人工设计
这与人类视觉系统类似:视网膜→边缘检测→形状识别→物体认知
全连接网络没有这种层次结构,必须同时学习所有复杂度
CNN的优缺点#
优点 |
缺点 |
|---|---|
保留空间结构信息 |
实现相对复杂 |
参数数量少 |
超参数选择敏感 |
平移不变性 |
计算复杂度高 |
局部连接 |
需要更多内存 |
分层特征提取 |
训练时间较长 |
从全连接到卷积的演进
卷积神经网络的设计直接针对全连接网络的局限性:
参数爆炸 → 参数共享大幅减少参数
空间信息丢失 → 局部连接保留空间结构
平移不变性差 → 平移不变性提高泛化能力
计算效率低 → 分层特征提取提高计算效率
这种演进体现了深度学习架构设计中的归纳偏置(Inductive Bias)思想:通过引入适合任务结构的先验知识,让模型更高效地学习。
下一步#
掌握了CNN基础后,下一节LeNet-5架构详解我们将分析第一个成功的CNN架构——LeNet-5。我们将看到:
理论概念如何转化为工程实践
1998年的设计为何至今仍不过时
经典架构中的设计智慧
让我们看看CNN如何从实验室走向银行支票识别系统!
参考文献#
Yann LeCun, Bernhard Boser, John S Denker, Donnie Henderson, Richard E Howard, Wayne Hubbard, and Lawrence D Jackel. Backpropagation applied to handwritten zip code recognition. Neural Computation, 1(4):541–551, 1989.
Yann LeCun, Léon Bottou, Yoshua Bengio, and Patrick Haffner. Gradient-based learning applied to document recognition. Proceedings of the IEEE, 86(11):2278–2324, 1998.
贡献者与修订历史
查看详细修订记录
-
4f5009f2026-04-28 - Heyan Zhu: docs: add detailed explanations for neural network concepts -
22312762026-04-28 - Heyan Zhu: feat(attention-mechanisms): restructure and enhance attention mechanisms documentation -
b20ef3e2026-04-28 - Heyan Zhu: docs: update pytorch practice section with detailed explanations and code examples -
59126f42026-04-26 - Heyan Zhu: docs(math-fundamentals): update content structure and add citations -
cec393d2025-12-11 - Heyan Zhu: docs: partially complete migration and restructure course materials